
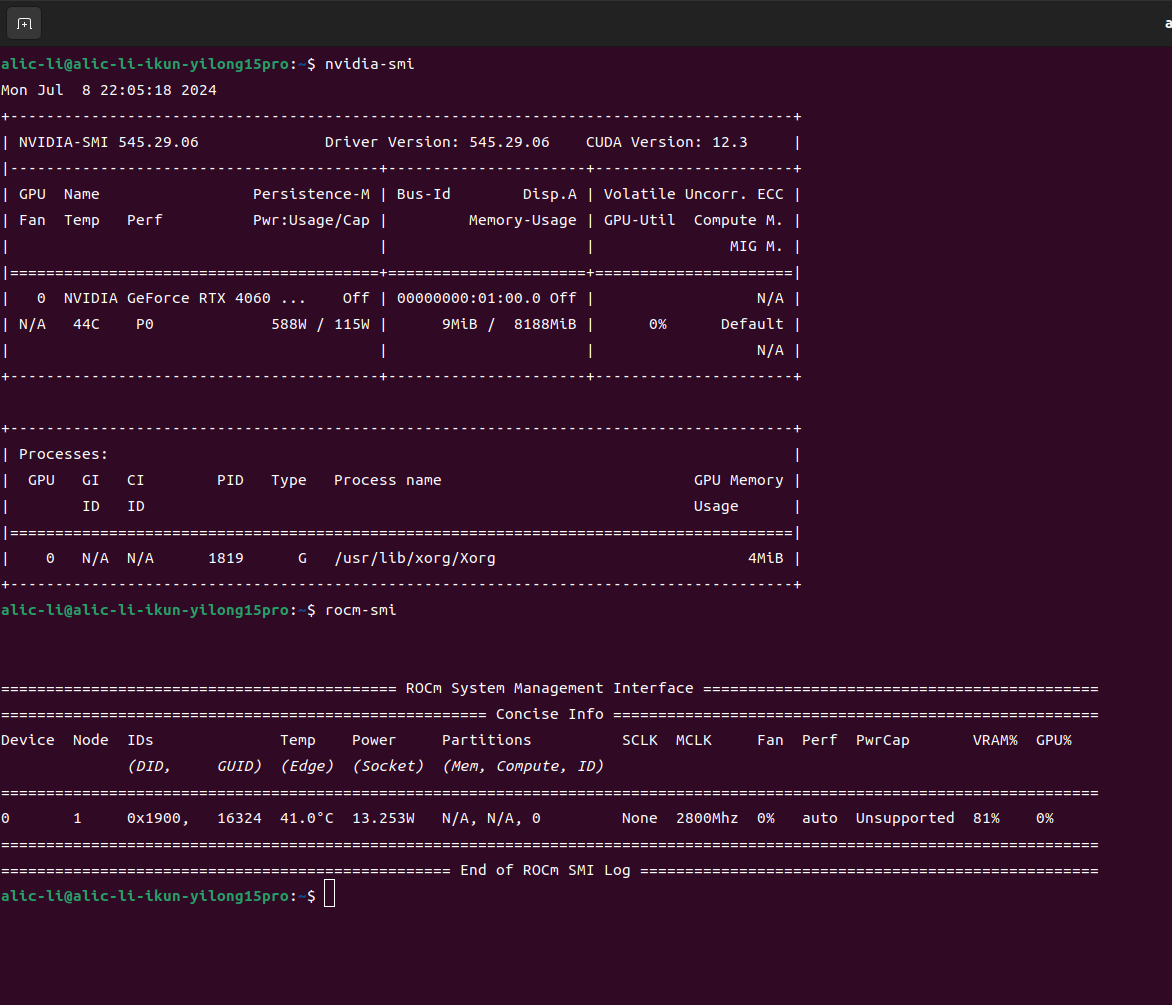
Test platform 🐔MECHREVO yilong 15pro 8845h with Radeon-780m integrated graphics🚀, 32Gddr5-5600mhz memory, RTX4060-laptop (Disabled by me in Bios, Because of Nvidia Fuck You!!!)😝
- Because I just graduated from high school this year, I bought an all-around laptop. I was originally a loyal Radeon user, but because AMD does not adapt the laptop’s mobile graphics card to the mainstream machine learning framework, my Radeon780M can perfectly install ROCm6.1 on Ubuntu, but!!! The ROCm software stack can be called normally, but pytorch said that this core is not supported by me at all. . . (As shown below) So I bought Uncle Huang’s 4060 laptop, and found that Uncle Huang’s card is really useful~😋

This official hip test example can run perfectly, and even the core can be identified, which is extremely abstract😂
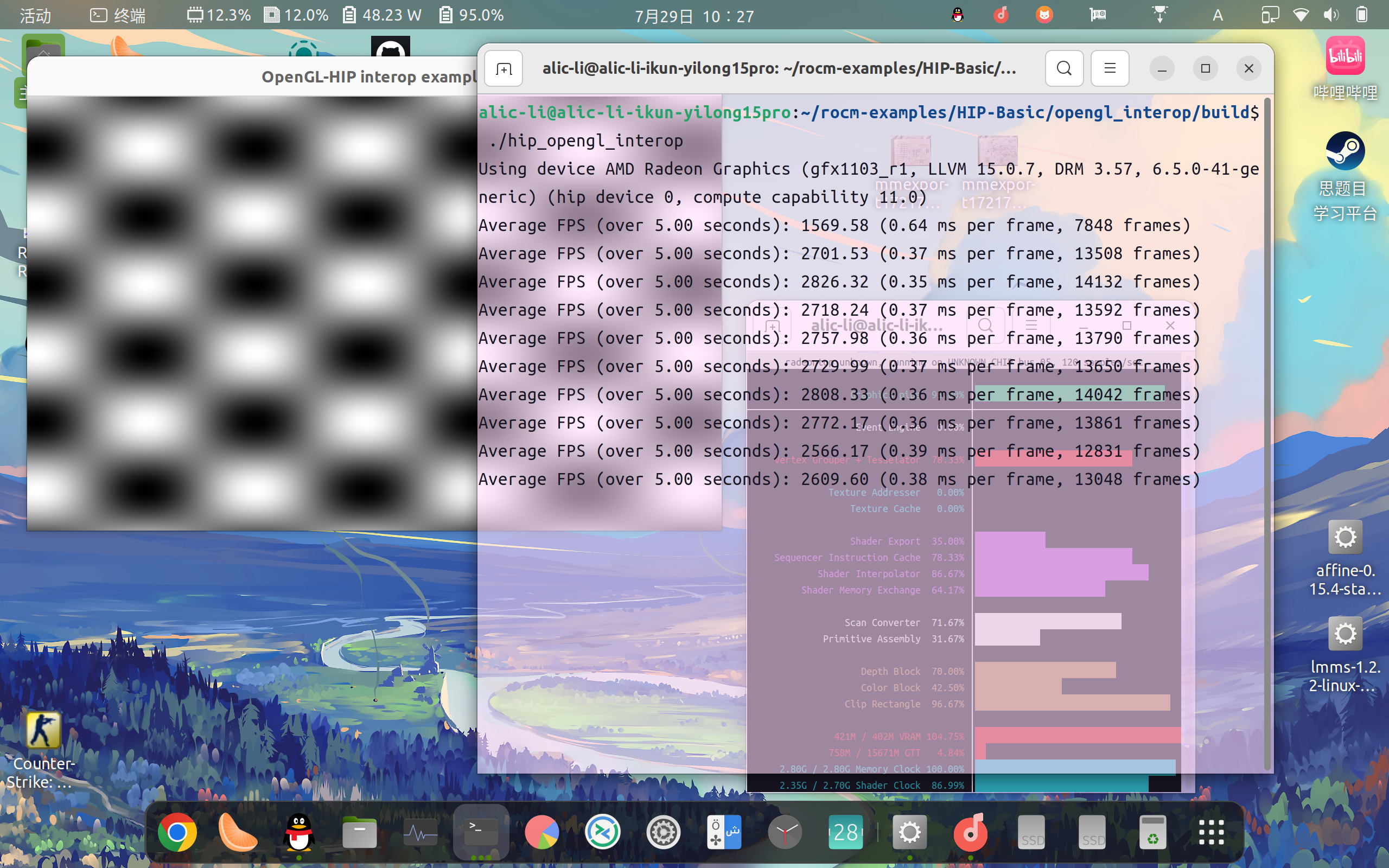
Let’s get started! ! ! 🤗
- Author’s warehouse address https://github.com/Ai00-X/ai00_server/
- If you run it, you can run it without installing torch, because it use Vulkan’s API, so it can basically run on any computer or graphics card, so let’s cheer for the Vulkan organization and the RWKV community! ! ! 🎉 And don’t forget my Mozilla organization🦊
- During the installation process, you only need to download the Releases of the corresponding operating system from the project repository, or you can compile it yourself to start it😊
- The documentation is very well written, so I won’t go into details here❤️
- Just run it in the project folder👀
|
|
- Open the browser and enter http://localhost:65530 to enter the management webui panel
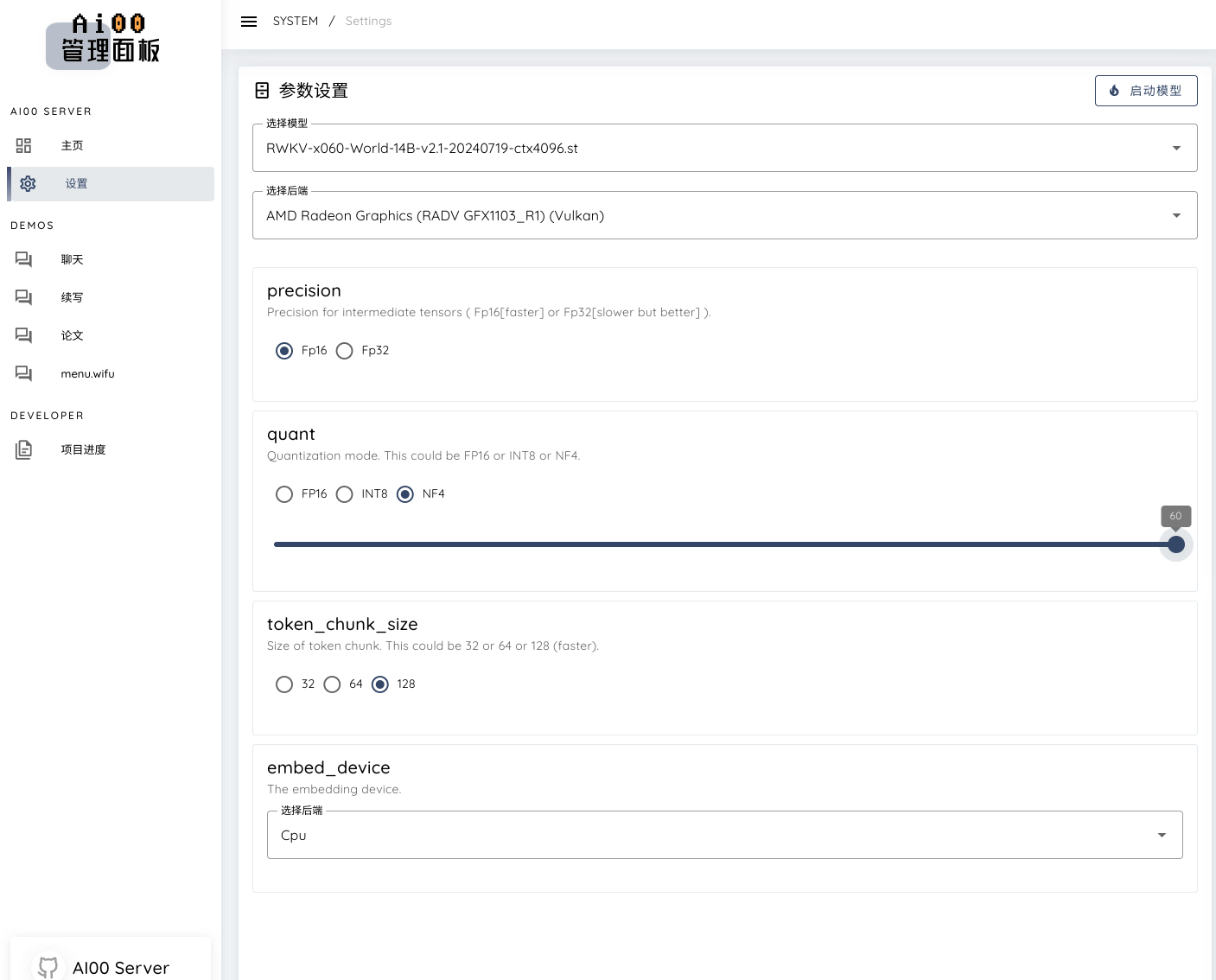
Parameter setting🤔
- As shown in the figure: we select the model file in the safe tensor format of 14b. If it is a .pth model file, it needs to be converted
- I can run 5 tokens/s with 32g memory and 14b using nf4 quantization, and the power consumption is only a little more than 40w, which is very amazing 🔥
- Can it be said that it can run 4090-level model parameters? 😜
Model conversion 📒
This project currently only supports Safetensors models with the .st suffix. Models with the .pth suffix saved through torch need to be converted before use.
-
Clone or download the
convert2ai00.pyorconvert_safetensors.pyprogram in this repository and install the corresponding dependent libraries (torchandsafetensors) -
Run the above program and specify the input and output paths
|
|
- If you don’t want to install Python or Torch, you can go to
web-rwkvand download the converterweb-rwkv-converterwhich does not depend on Python or Torch
|
|
- According to the above steps, put the converted
.stmodel file in theassets/models/path and modify the model path inassets/Config.toml
Model path💾
You can modify the model configuration in ./assets/configs/Config.toml, including model path, number of quantization layers, etc.
|
|
Run the model
- I think the function of writing papers is a major feature of the AI00 project~ 🥰
- It feels good to write~ It has a strong flavor of Chinese textbooks🤣
- And it can automatically generate outlines✨
- But remember to generate the outlines in batches with the same title. I put them all in at the same time and encountered some minor bugs. 3~4 points each time👀